
Cassandra学习
安装
1、下载
1 | 打开官网,选择下载频道 https://cassandra.apache.org/download/ |
2、新建数据存储目录,data目录
1 | # 如果不配置数据目录默认为$CASSANDRA_HOME/data/data; |
3、新建日志目录,commitlog目录
1 | # 如果不配置日志目录,默认为:$CASSANDRA_HOME/data/commitlog; |
4、新建缓存目录,saved_caches目录
1 | # 如果不配置日志目录,默认为:$CASSANDRA_HOME/data/saved_caches; |
- 注意:- 的后面要跟一个空格,这是yaml的语法;
启动
前提条件:JDK && Python
1、不会创建交互式会话,它只是在前台运行Cassandra,而是作为服务器进程运行。 要与Cassandra进行交互,可以在另一个终端窗口中启动CLI会话。
1 | bin % ./cassandra -f |
2、进入cqlsh
1 | bin % ./cqlsh |
3、查看是否启动成功
1 | ps -ef|grep cassandra |
数据存储结构
Cassandra 的数据模型是基于列族(Column Family)的四维或五维模型。它借鉴了 Amazon 的 Dynamo 和 Google’s Big Table 的数据结构和功能特点,采用Memtable的方式进行存储。在 Cassandra 写入数据之前,需要先记录日志 ( Commitlog),然后数据开始写入到 Column Family 对应的 Memtable 中,Memtable 是一种按照 key 排序数据的内存结构,在满足一定条件时,再把 Memtable 的数据批量的刷新到磁盘上,存储为 SSTable 。
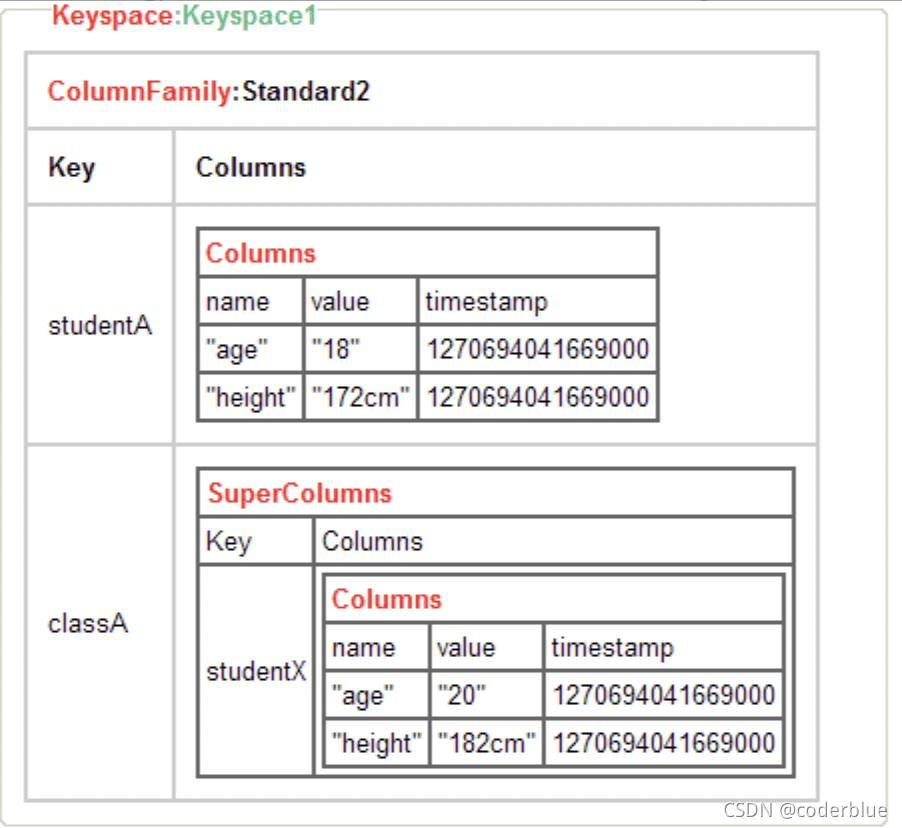
Keyspace
相当于关系数据库中的 Schema 或 database,用于存放 ColumnFamily 的容器,键空间包含一个或多个列族(Column Family)
注意:键空间 (KeySpace) 创建的时候可以指定一些属性:副本因子,副本策略,Durable_writes(是否启用 CommitLog 机制)
ColumnFamily
列族,一个简单的结构用来分组Column和SuperColumn。
用于存放 Column 的容器,类似关系数据库中的 table 的概念 。
ColumnFamily是一种可以包含无限数量的行(row)的结构
1 | // 这是一个ColumnFamily |
注意:ColumnFamily没有固定模式(schema)。并没有预先定义行包含了哪些Column。这就是Cassandra无模式的表现( This is the schemaless aspect of Cassandra)。
Column
Cassandra 的最基本单位。由name , value , timestamp组成。另外name和value都是二进制的(技术上指byte[]),并且可以是任意长度。

SuperColumn
它是一个特列殊的 Column, 它的 Value 值可以包函多个Column,如下图所示:

同Coulmn区别:
Column和SuperColumn都是拥有name、value的元组。
- 最大的不同在于标准Column的value是一个“字符串”,而 SuperColumn的value是一个包含多个Column的map。因此它们的value包含的是不同类型的数据。
- SuperColumn没有时间戳。
rowkey
ColumnFamily 中的每一行都用Row Key(行键)来标识,这个相当于关系数据库表中的主键,并且总是被索引的。
举个栗子,假如我有这么一个 table,叫做 ks.potato,该 table 总共有四个 field, 分别是 pk, ck, field1, field2。其中 pk,ck 是 key
| ks.potato |
|---|
| pk -> key 1 |
| ck -> key 2 |
| field1 |
| field2 |
CQL 插入这个表
1 | CREATE TABLE ks.potato ( |
向这张表里面写入一行数据
1 | INSERT INTO ks.potato |
那这行数据在 sstable 是怎么是储存的呢 ?
1 | [ |
可以看到,
- key1 决定了这行数据在哪个 partition,所以是 partition key。
- key2 决定数据在这个partition的位置,是 clustering key,同时会让一个分区内的数据进行排序。
- (key1, key2) 一起唯一标识了这一行,叫做 primary key,也叫做 row key。
Primary Key
Cassandra可以使用PRIMARY KEY 关键字创建主键,主键分为2种:
Single column Primary Key
如果 Primary Key 由一列组成,那么称为 Single column Primary KeyComposite Primary Key
如果 Primary Key 由多列组成,那么这种情况称为 Compound Primary Key 或 Composite Primary Key。比如例子中的 primary key 包括了两个 column (pk, ck), 那它就是一个 composite key。
列族具有以下属性 :
- keys_cached - 它表示每个SSTable保持缓存的位置数。
- rows_cached - 它表示其整个内容将在内存中缓存的行数。
- preload_row_cache -它指定是否要预先填充行缓存。
column key
column name
数据存放规则
data:存储真正的数据文件,既后面的SStable文件,可以指定多个目录。
commitlog:存储未写入SSTable中的数据(在每次写入之前先放入日志文件)。
cache:存储系统中的缓存数据(在服务重启的时候从这个目录中加载缓存数据)。
命令操作
help 帮助
输入命令,可以查看cqlsh 支持的命令
1 | cqlsh> help |
如下:
1 | CQL help topics: |
DESCRIBE
此命令配合 一些内容可以输入信息
1 | cqlsh> DESCRIBE cluster; |
输出:
1 | Cluster: Test Cluster |
DESCRIBE Keyspaces 列出集群中的所有Keyspaces(键空间)
1 | DESCRIBE keyspaces; |
DESCRIBE tables 列出键空间的所有表
效果,当前没有创建任何的键空间,这里显示的默认内置的表
1 | --------------------------- |
指定键空间 ,这里使用 system_traces
1 | cqlsh> USE system_traces; |
列出system_traces 下的 sessions信息
1 | cqlsh:system_traces> DESCRIBE sessions; |
输出:
1 | CREATE TABLE system_traces.sessions ( |
Keyspace
1、创建Keyspace
1 | CREATE KEYSPACE <identifier> WITH <properties>; |
更具体的语法:
1 | Create keyspace KeyspaceName with replicaton={'class':strategy name,'replication_factor': No of replications on different nodes}; |
要填写的内容:
- KeyspaceName 代表键空间的名字
- strategy name 代表副本放置策略,内容包括:简单策略、网络拓扑策略,选择其中的一个。
- No of replications on different nodes 代表 复制因子,放置在不同节点上的数据的副本数。
编写完成的创建语句 创建一个键空间名字为:school,副本策略选择:简单策略 SimpleStrategy,副本因子:3
1 | CREATE KEYSPACE school WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3}; |
如图所示:
输入 DESCRIBE school 查看键空间的创建语句,代码:

2、连接Keyspace
1 | USE <identifier>; |
编写完整的连接Keyspace语句,连接school 键空间
1 | use school; |
3、修改键空间
1 | ALTER KEYSPACE <identifier> WITH <properties> |
编写完整的修改键空间语句,修改school键空间,把副本引子 从3 改为1
1 | ALTER KEYSPACE school WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 1}; |
4、删除键空间
1 | DROP KEYSPACE <identifier> |
完整删除键空间语句,删除school键空间
1 | DROP KEYSPACE school |
表操作
1、查看键空间下所有表
创建school键空间,再查看:
1 | DESCRIBE TABLES; |
如果当前键空间下没有任何表,则返回空;
2、创建表
1 | CREATE (TABLE | COLUMNFAMILY) <tablename> ('<column-definition>' , '<column-definition>') |
完整创建表语句,创建student 表,student包含属性如下: 学生编号(id), 姓名(name),年龄(age),性别(gender),家庭地址(address),interest(兴趣),phone(电话号码),education(教育经历) id 为主键,并且为每个Column选择对应的数据类型。 注意:interest 的数据类型是set ,phone的数据类型是list,education 的数据类型是map
1 | CREATE TABLE student( |
如下所示:
1 | cqlsh:school> CREATE TABLE student( |
3、修改表结构
添加列,语法:
1 | ALTER TABLE table name ADD new column datatype; |
给student添加一个列email代码:
1 | ALTER TABLE student ADD email text; |
删除列,语法
1 | ALTER table name DROP columnname; |
删除student中列phone:
1 | ALTER table student DROP phone; |
删除表
1 | DROP TABLE <tablename> |
清空表
1 | TRUNCATE <tablename> |
CURD
ALLOW FILTERING
ALLOW FILTERING是一种非常消耗计算机资源的查询方式。 如果表包含例如100万行,并且其中95%具有满足查询条件的值,则查询仍然相对有效,这时应该使用ALLOW FILTERING。
如果表包含100万行,并且只有2行包含满足查询条件值,则查询效率极低。Cassandra将无需加载999,998行。如果经常使用查询,则最好在列上添加索引。
ALLOW FILTERING在表数据量小的时候没有什么问题,但是数据量过大就会使查询变得缓慢。查询所有数据
查询
当前student表有2行数据,全部查询出来,代码:
1 | -- SELECT FROM <table name> WHERE <condition>; |
查询时排序
- 必须有第一主键的=号查询cassandra的第一主键是决定记录分布在哪台机器上,cassandra只支持单台机器上的记录排序。
- 只能根据第二、三、四…主键进行有序的,相同的排序。
- 不能有索引查询cassandra的任何查询,最后的结果都是有序的,内部就是这样存储的。
现在使用 testTab表,来测试排序
1 | select * from testtab where key_one = 12 order by key_two; --正确 |
索引列 支持 like
主键支持 group by
分页查询
使用limit 关键字来限制查询结果的条数 进行分页
添加数据
语法
1 | INSERT INTO <tablename>(<column1 name>, <column2 name>....) VALUES (<value1>, <value2>....) USING <option> |
示例:
1 | INSERT INTO student (id,address,age,gender,name,interest, phone,education) VALUES (1011,'中山路21号',16,1,'Tom',{'游泳', '跑步'},['010-88888888','13888888888'],{'小学' : '城市第一小学', '中学' : '城市第一中学'}) ; |
添加带过期时间数据:
1 | INSERT INTO student (id,address,age,gender,name,interest, phone,education) VALUES (1030,'朝阳路30号',20,1,'Cary',{'运动', '游戏'},['020-7777888','139876667556'],{'小学' :'第30小学','中学':'第30中学'}) USING TTL 60; |
更新列数据
更新表中的数据,可用关键字:
Where- 选择要更新的行Set- 设置要更新的值Must- 包括组成主键的所有列
在更新行时,如果给定行不可用,则UPDATE创建一个新行
语法:
1 | UPDATE <tablename> |
把student_id = 1012 的数据的gender列 的值改为1,代码:
1 | UPDATE student set gender = 1 where id = 1012; |
set
添加一个元素
在student中interest列是set类型,添加一个元素,使用UPDATE命令 和 ‘+’ 操作符
代码:
1 | UPDATE student SET interest = interest + {'游戏'} WHERE id = 1012; |
删除一个元素
使用UPDATE命令 和 ‘-’ 操作符
代码:
1 | UPDATE student SET interest = interest - {'电影'} WHERE id = 1012; |
删除所有元素
可以使用UPDATA或DELETE命令,效果一样
代码:
1 | UPDATE student SET interest = {} WHERE id = 1012; |
或
1 | DELETE interest FROM student WHERE id = 1012; |

list
更新list类型数据
在student中phone列是list类型
使用UPDATE命令向list插入值
1 | UPDATE student SET phone = ['020-66666666', '13666666666'] WHERE id = 1012; |
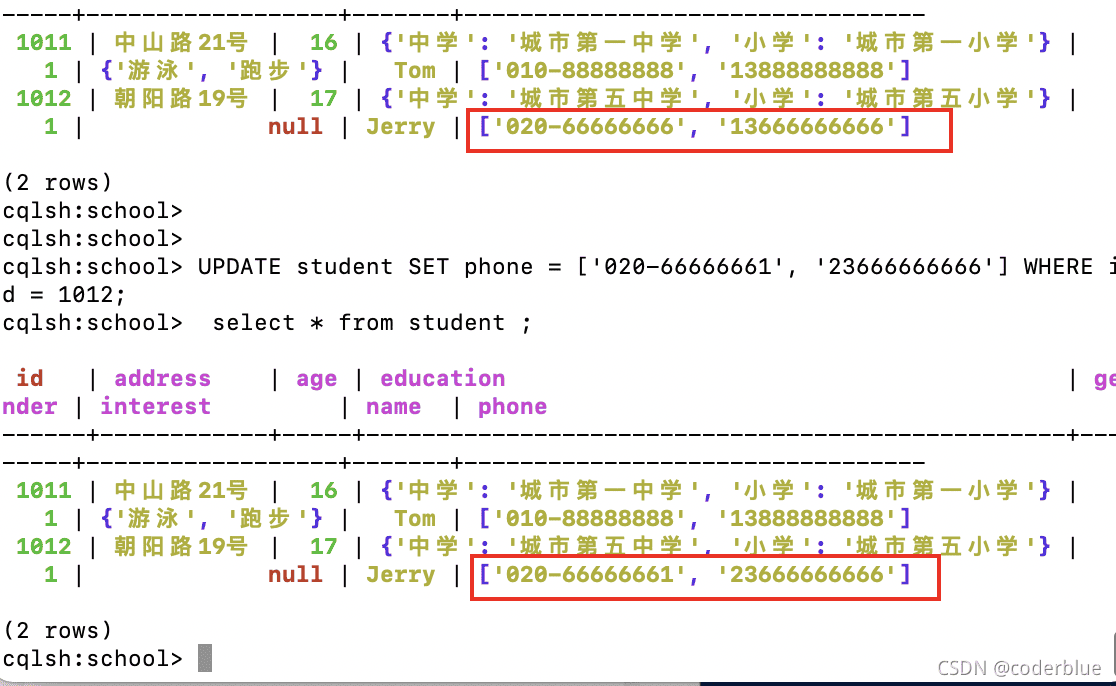
2)在list前面插入值
1 | UPDATE student SET phone = [ '030-55555555' ] + phone WHERE id = 1012; |
可以看到新数据的位置在旧数据的前面,效果:

3)在list后面插入值
1 | UPDATE student SET phone = phone + [ '040-33333333' ] WHERE id = 1012; |
列表索引
使用列表索引设置值,覆盖已经存在的值
现在把phone中下标为2的数据,也就是 “13666666666”替换,代码:
1 | UPDATE student SET phone[2] = '050-22222222' WHERE id = 1012; |
删除特定位置值
使用DELETE命令和索引删除某个特定位置的值
1 | DELETE phone[2] FROM student WHERE id = 1012; |
移除list中所有的特定值
使用UPDATE命令和 '-'移除list中所有的特定值
1 | UPDATE student SET phone = phone - ['020-66666666'] WHERE id = 1012; |
map
更新map类型数据
1)使用Insert或Update命令
1 | UPDATE student SET education = {'中学': '城市第五中学', '小学': '城市第五小学'} WHERE id = 1012; |
2)使用UPDATE命令设置指定元素的value
1 | UPDATE student SET education['中学'] = '爱民中学' WHERE id = 1012; |
3)增加map元素
可以使用如下语法增加map元素。如果key已存在,value会被覆盖,不存在则插入
1 | UPDATE student SET education = education + { '幼儿园' : '大海幼儿园', '中学': '科技路中学'} WHERE id = 1012; |
覆盖“中学”为“科技路中学”,添加“幼儿园”数据。
4)删除元素
可以用DELETE 和 UPDATE 删除Map类型中的数据
1 | DELETE education['幼儿园'] FROM student WHERE id = 1012; |
使用UPDATE删除数据
1 | UPDATE student SET education=education - {'中学','小学'} WHERE id = 1012; |
删除行
语法:
1 | DELETE FROM <identifier> WHERE <condition>; |
删除student中student_id=1012 的数据,代码:
1 | DELETE FROM student WHERE student_id=1012; |
批量操作
作用:把多次更新操作合并为一次请求,减少客户端和服务端的网络交互。 batch中同一个partition key的操作具有隔离性
使用BATCH,您可以同时执行多个修改语句(插入,更新,删除)
1 | BEGIN BATCH |
示例:
1 | BEGIN BATCH |
索引
上面创建student的时候,把student_id 设置为primary key 在Cassandra中的primary key是比较宏观概念,用于从表中取出数据。primary key可以由1个或多个column组合而成。
不要在以下情况使用索引:
- 这列的值很多的情况下,因为你相当于查询了一个很多条记录,得到一个很小的结果。
- 表中有couter类型的列
- 频繁更新和删除的列
- 在一个很大的分区中去查询一条记录的时候(也就是不指定分区主键的查询)
五种类型Key
1、Primary Key
是用来获取某一行的数据, 可以是单一列(Single column Primary Key)或者多列(Composite Primary Key)。
在 Single column Primary Key 决定这一条记录放在哪个节点。
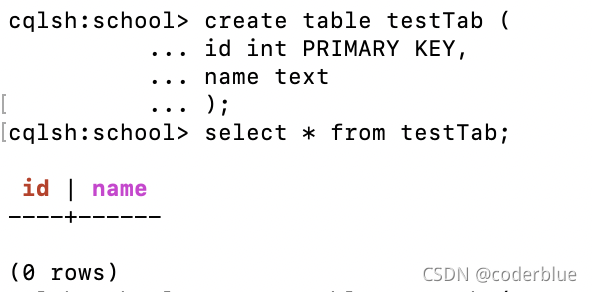
例如:
1 | create table testTab ( |
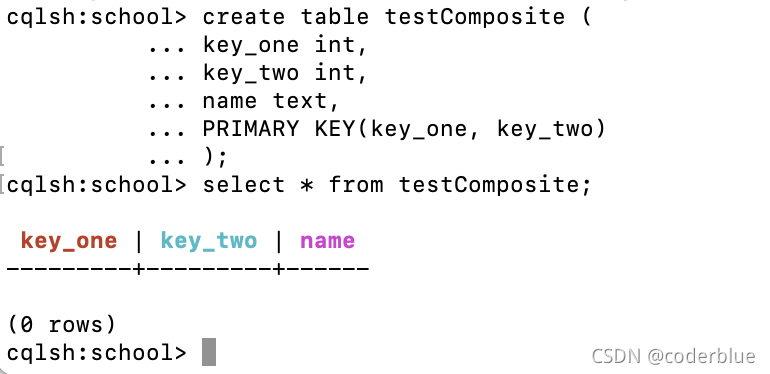
2、Composite Primary Key
如果 Primary Key 由多列组成,那么这种情况称为 Compound Primary Key 或 Composite Primary Key。
例如:
1 | create table testComposite ( |
执行创建表后,查询testTab,会发现key_one和key_two 的颜色与其他列不一样,效果:
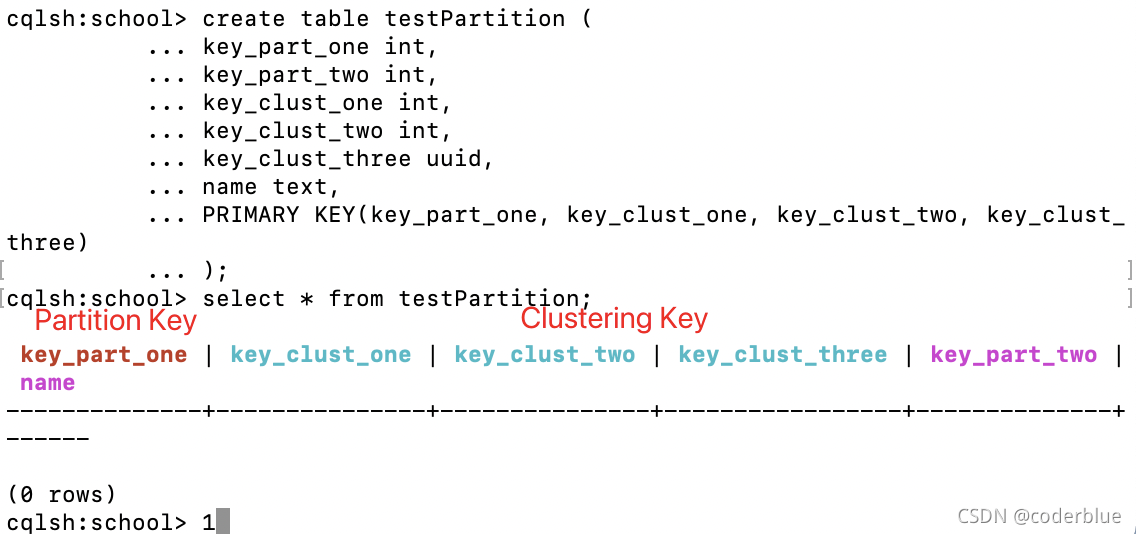
3、Partition Key
在组合主键的情况下(上面的例子),第一部分称作Partition Key(key_one就是partition key),第二部分是CLUSTERING KEY(key_two)
Cassandra会对Partition key 做一个hash计算,并自己决定将这一条记录放在哪个节点。
例如:
1 | create table testPartition ( |
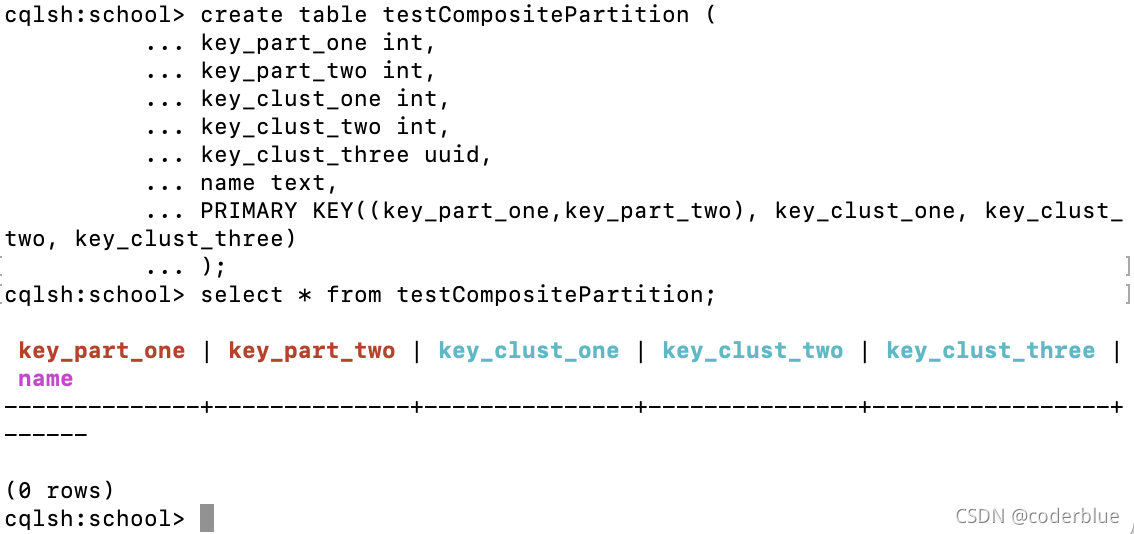
4、Composite Partition key
如上3中,如果 Partition key 由多个字段组成,称之为 Composite Partition key
1 | create table testCompositePartition ( |
5、Clustering Key
决定同一个分区内相同 Partition Key 数据的排序,默认为升序,可以在建表语句里面手动设置排序的方式
创建索引
1、语法
1 | CREATE INDEX <identifier> ON <tablename> |
为student的 name 添加索引,索引的名字为:sname, 代码:
1 | CREATE INDEX sname ON student (name); |
为student 的age添加索引,不设置索引名字,代码
1 | CREATE INDEX ON student (age); |
可以发现 对age创建索引,没有指定索引名字,会提供一个默认的索引名:student_age_idx。
1 | cqlsh:school> describe student; |
索引原理:
Cassandra之中的索引的实现相对MySQL的索引来说就要简单粗暴很多了。Cassandra自动新创建了一张表格,同时将原始表格之中的索引字段作为新索引表的Primary Key!并且存储的值为原始数据的Primary Key
集合列创建索引
给集合列设置索引
1 | CREATE INDEX ON student(interest); -- set集合添加索引 |
删除索引
1 | DROP INDEX <identifier> |
删除student的sname 索引,代码
1 | DROP INDEX sname; |
查询时使用索引
Cassandra对查询时使用索引有一定的要求,具体如下:
- Primary Key 只能用 = 号查询
- 第二主键 支持= > < >= <=
- 索引列 只支持 = 号
- 非索引非主键字段过滤可以使用ALLOW FILTERING
创建表
1 | create table testTab ( |
第一主键查询
只能用 = 号查询
1 | select * from testtab where key_one=4; |
使用第二主键查询
注意⚠️:不要单独对key_two 进行 查询,
1 | select * from testtab where key_two = 8; |
报错:
1 | InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING" |
可知,如果需要单独对key_two查询,则要使用 ALLOW FILTERING(不推荐)
推荐做法:在查询第二主键时,前面先写上第一主键,有点像MySQL索引的最左前缀法则
1 | select * from testtab where key_one=12 and key_two = 8 ; |
索引列
只支持=号
1 | select * from testtab where age = 19; -- 正确 |
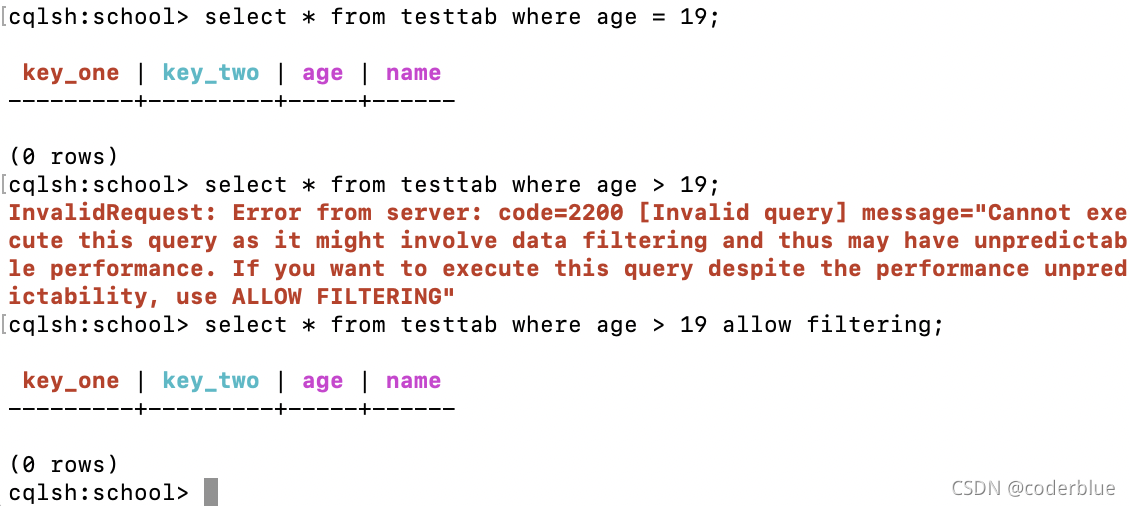
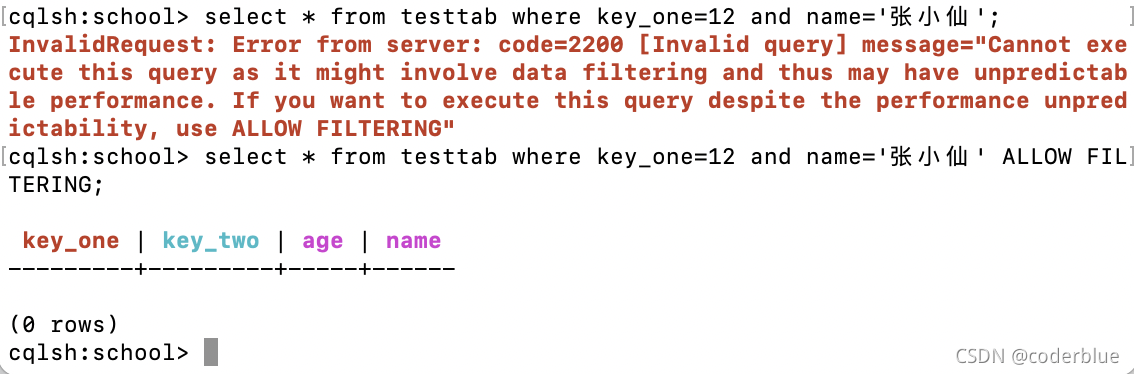
普通列
非索引非主键字段,如此表name是普通列,在查询时需要使用ALLOW FILTERING。
1 | select * from testtab where key_one=12 and name='张小仙'; --报错 |
集合列
使用student表来测试集合列上的索引使用。
假设已经给集合添加了索引,就可以使用where子句的CONTAINS条件按照给定的值进行过滤。
1 | -- 查询set集合 |
Prepared statements
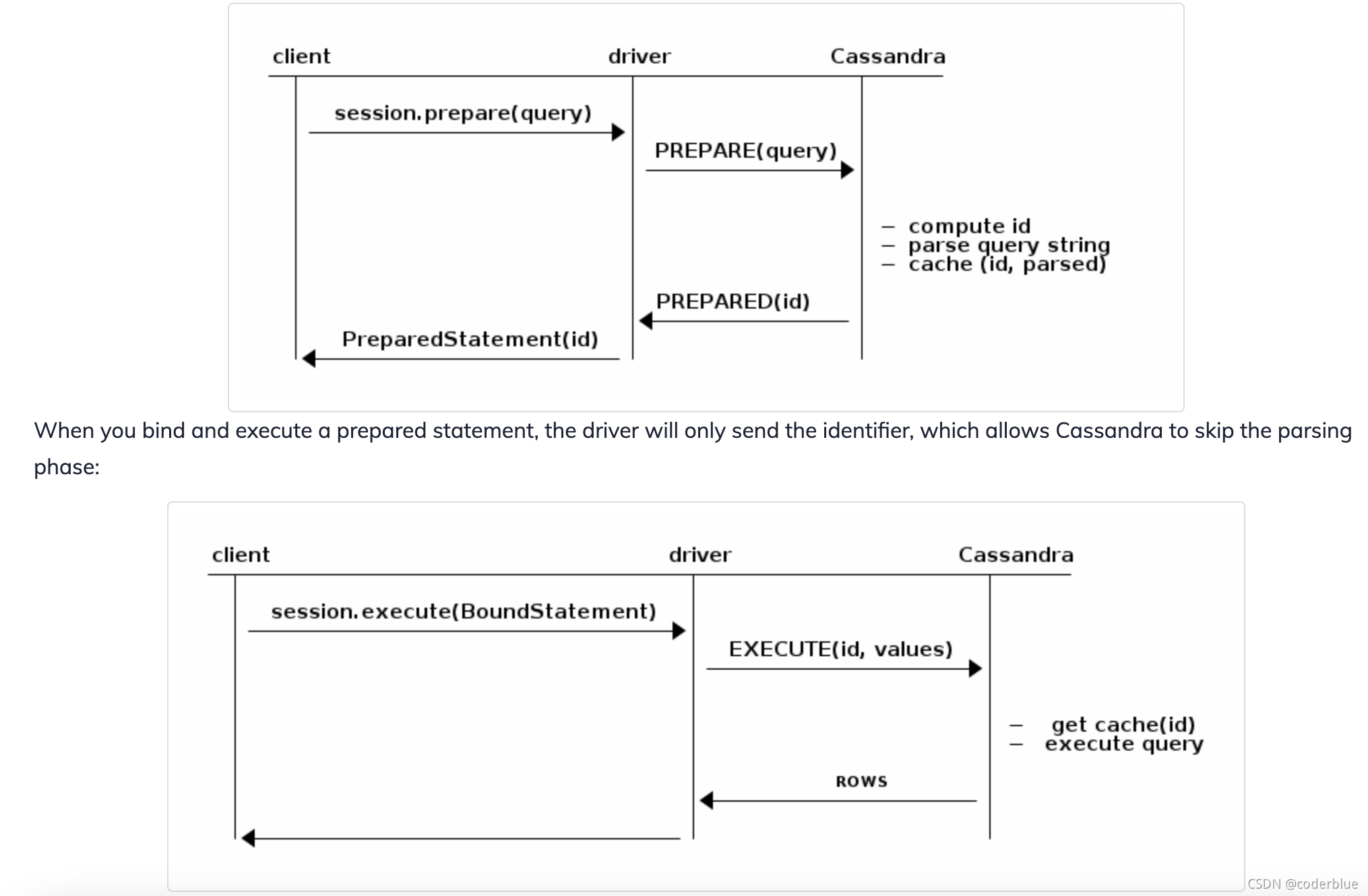
基本原理
1 | 预编译statement的时候,Cassandra会解析query语句,缓存解析的结果并返回一个唯一的标志。当绑定并且执行预编译statement的时候,驱动只会发送这个标志,那么Cassandra就会跳过解析query语句的过程。 应保证query语句只应该被预编译一次,缓存PreparedStatement 到我们的应用中(PreparedStatement 是线程安全的);如果我们对同一个query语句预编译了多次,那么驱动输出印警告日志; 如果一个query语句只执行一次,那么预编译不会提供性能上的提高,反而会降低性能,因为是两次请求,那么此时可以考虑用 simple statement 来代替。 |
数据存储
Cassandra的数据包括在内存中的和磁盘中的数据
这些数据主要分为三种: CommitLog:主要记录客户端提交过来的数据以及操作。这种数据被持久化到磁盘中,方便数据没有被持久化到磁盘时可以用来恢复。 Memtable:用户写的数据在内存中的形式,它的对象结构在后面详细介绍。其实还有另外一种形式是BinaryMemtable 这个格式目前 Cassandra 并没有使用,这里不再介绍了。 SSTable:数据被持久化到磁盘,这又分为 Data、Index 和 Filter 三种数据格式。
CommitLog 数据格式
Cassandra在写数据之前,需要先记录日志,保证Cassandra在任何情况下宕机都不会丢失数据,这就是CommitLog日志。要写入的数据按照一定格式组成 byte 组数,写到 IO 缓冲区中定时的被刷到磁盘中持久化。Commitlog是server级别的。每个Commitlog文件的大小是固定的,称之为一个CommitlogSegment。
当一个Commitlog文件写满以后,会新建一个的文件。当旧的Commitlog文件不再需要时,会自动清除。
Memtable 内存中数据结构
数据写入的第二个阶段,MemTable是一种内存结构,当数据量达到块大小时,将批量flush到磁盘上,存储为SSTable。优势在于将随机IO写变成顺序IO写,降低大量的写操作对于存储系统的压力。每一个columnfamily对应一个memtable。也就是每一张表对应一个。用户写的数据在内存中的形式,
SSTable 数据格式
SSTable是Read Only的,且一般情况下,一个ColumnFamily会对应多个SSTable,当用户检索数据时,Cassandra使用了Bloom Filter,即通过多个hash函数将key映射到一个位图中,来快速判断这个key属于哪个SSTable。
为了减少大量SSTable带来的开销,Cassandra会定期进行compaction,简单的说,compaction就是将同一个ColumnFamily的多个SSTable合并成一个SSTable。
在Cassandra中,compaction主要完成的任务是:
- 垃圾回收: cassandra并不直接删除数据,因此磁盘空间会消耗得越来越多,compaction 会把标记未删除的数据真正删除;
- 合并SSTable:compaction 将多个 SSTable 合并为一个(合并的文件包括索引文件,数据文件,bloom filter文件),以提高读操作的效率;
- 生成 MerkleTree:在合并的过程中会生成关于这个ColumnFamily中数据的 MerkleTree,用于与其他存储节点对比以及修复数据。
Cassandra的重要知识点
Cassandra的集群中每一台机器都是对等的,不存在主、从节点的区分,集群中任何一台机器出现故障是,整个集群系统不会受到影响。
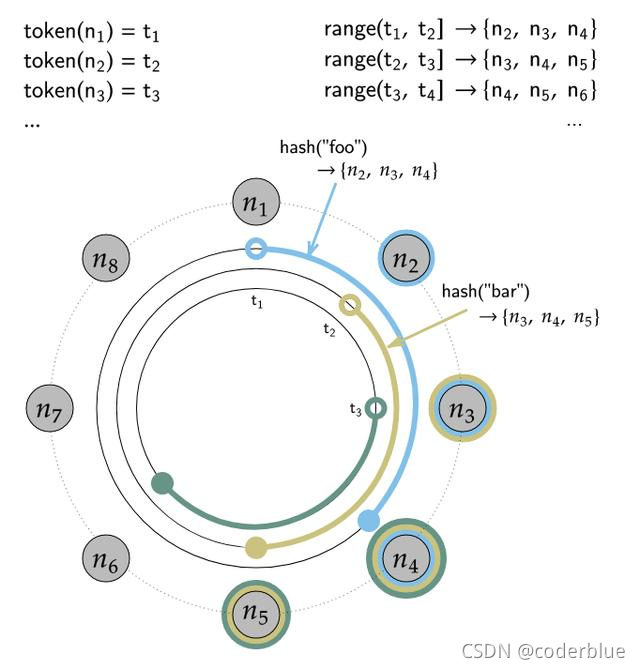
一致哈希
一致性哈希是Cassandra搭建集群的基础,一致性哈希可以降低分布式系统中,数据重新分布的影响。
在Cassandra中,每个表有Primary Key外,还有一个叫做Partition Key,Partition Key列的Value会通过Cassandra一致性算法得出一个哈希值,这个哈希值将决定这行数据该放到哪个节点上。
每个节点拥有一段数字区间,这个区间的含义是:如果某行记录的Partition Key的哈希值落在这个区间范围之内,那么该行记录就该被存储到这个节点上。
如果简单的使用哈希值,可能会引起数据分布不均匀的问题,为了解决这个问题,一致性哈希提出虚拟节点的概念,简单的理解就是:将某个节点根据一个映射算法,映射出若干个虚拟子节点出来,再把这些节点分布在哈希环上面,保存数据时,如果通过一致性哈希计算落到某个虚拟子节点上,这条记录就会被存在这个虚拟子节点的母节点上。
Token:在Cassandra,每个节点都对应一个token,相当于hash环中的一个节点地址。在Cassandra的配置文件中有一项配置叫做:num_tokens,这个配置项可以控制一个节点映射出来的虚拟节点的个数。
Range:在Cassandra中,每一个节点负责处理hash环的一段数据,范围是从上一个节点的Token到本节点Token,这就是Range
在健康的集群中,可以通过自带的工具nodetool查看集群的哈希环具体情况,命令为:nodetool ring。
这里我们使用cassandra官方文档中一张图来说明
Gossip内部通信协议
Cassandra使用Gossip的协议维护集群的状态,这是个端对端的通信协议。通过Gossip,每个节点都能知道集群中包含哪些节点,以及这些节点的状态,
Gossip进程每秒运行一次,与最多3个其他节点交换信息,这样所有节点可很快了解集群中的其他节点信息。
参考链接:


